Introduction
Day-long (audio-)recordings of children are increasingly common, but there is no scientific standard formatting that can benefit the organization and analyses of such data. ChildRecordData provides standardizing specifications and tools for the storage and management of day-long recordings of children and their associated meta-data and annotations.
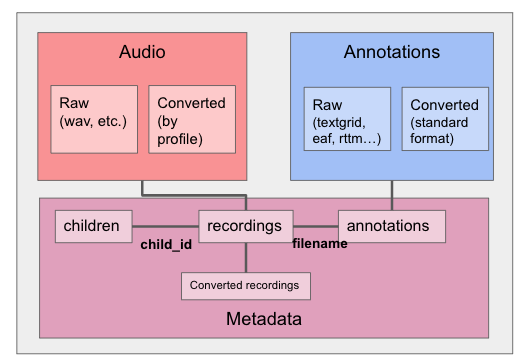
File organization structure
We assume that the data include three very different types:
Audio, of which we distinguish the raw audio extracted from the hardware; and a version that has been converted into a standardized format. These audios are the long-form ones. At the time being, we do not foresee including clips extracted from these long-form audios, and assume that any such process will generate some form of annotation that can then be re-cast temporally to the long-form audio.
Annotations, of which we again distinguish raw and standardized versions. At present, we can import from Praat’s textgrid, ELAN’s eaf, and VTC’s rttm format.
Metadata corresponding to the children, recordings, and annotations, which will therefore also describe the converted recordings.
Available tools
Day-long audiorecordings are often collected using a LENA recorder, and analyzed with the LENA software. However, open source alternatives to the LENA commercial environment are emerging, some of which are shown in the following figure.
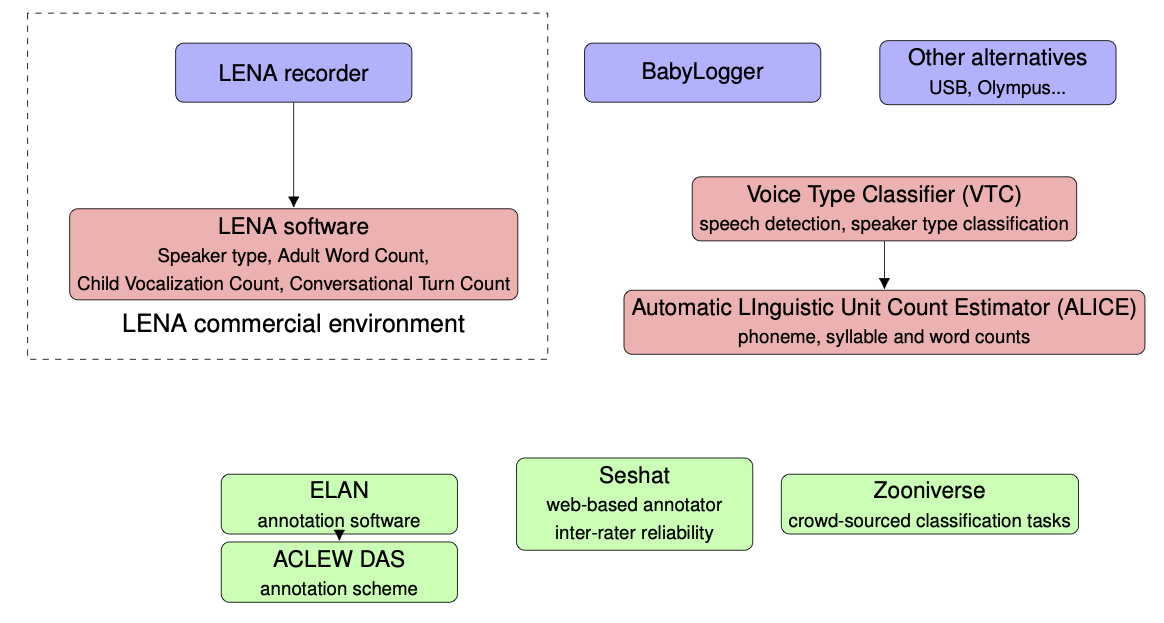
Overview of some tools in the day-long recordings environment
For instance, alternative hardware includes the babylogger and any other light-weight recording device with enough battery and storage to record over several hours.
Alternative automated analysis options include the Voice Type Classifier, which segments the audio into different talker types (key child, female adult, etc) and ALICE, an automated linguistic unit counter.
As for manual annotation options, ELAN can be used, for instance employing the ACLEW DAS annotation scheme; CHAT annotations are also supported.
Assignment of annotation to individuals and evaluation can be done using Seshat. Finally, Zooniverse can be used to crowd-source certain aspects of the classification with the help of citizen scientists.
In this context, we provide tools and a procedure to:
Validate datasets (making sure that metadata, recordings and annotations are in the right place and format)
Convert your raw recordings into the desired format
Import annotations (from the LENA, ELAN, Praat, VTC/ALICE/VCM rttms, CHAT files) into a standardized format
Generate reliability metrics by comparing annotators (confusion matrices, agreement coefficients, pyannote metrics)
Extract metrics from the annotations (e.g. average vocalization rates, durations, etc.)
Sample segments of the recordings to annotate from a set of sampling algorithms
- Add clips to an annotation pipeline in Zooniverse, and retrieve the
ensuing annotations
(And more!)
Citing this work
If you are using this project for your research, please cite our introductory paper:
@article{gautheron_rochat_cristia_2021,
title={Managing, storing, and sharing long-form recordings and their annotations},
url={https://psyarxiv.com/w8trm},
DOI={10.31234/osf.io/w8trm},
publisher={PsyArXiv},
author={Gautheron, Lucas and Rochat, Nicolas and Cristia, Alejandrina},
year={2021},
month={May}
}
Community
You can ask for help, suggest ideas about the package or share code that relies on it with others on GitHub discussions.
Bugs should be reported on GitHub too.