Samplers
Overview
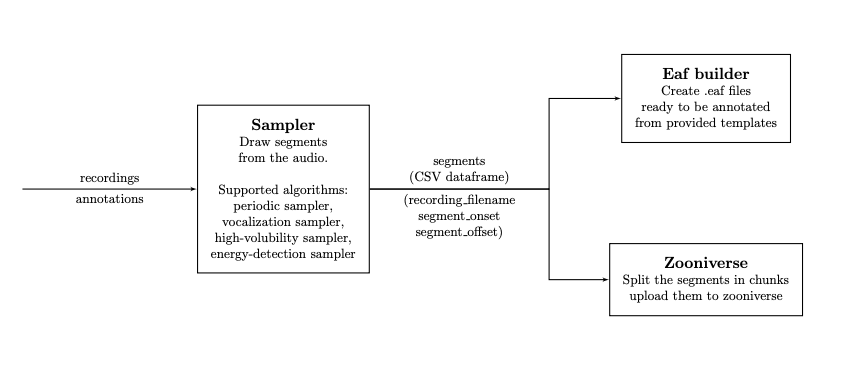
Sampling audio segments to be annotated with ChildProject.
A sampler draws segments from the recordings, according to the algorithm and the parameters defined by the user. The sampler will produce two files into the destination folder :
segments_YYYYMMDD_HHMMSS.csv, a CSV dataframe of all sampled segments, with three columns:recording_filename,segment_onsetandsegment_offset.
parameters_YYYYMMDD_HHMMSS.yml, a Yaml file with all the parameters that were used to generate the samples.
If the folder destination does not exist, it is automatically created in the process.
Several samplers are implemented in our package, which are listed below.
The samples can then feed downstream pipelines such as the Zooniverse pipeline or the ELAN builder.
$ child-project sampler --help
usage: child-project sampler [-h] [--recordings RECORDINGS]
[--exclude EXCLUDE]
path destination
{custom,periodic,random-vocalizations,energy-detection,high-volubility,conversations}
...
positional arguments:
path path to the dataset
destination segments destination
{custom,periodic,random-vocalizations,energy-detection,high-volubility,conversations}
sampler
custom custom sampling
periodic periodic sampling
random-vocalizations
random sampling
energy-detection energy based activity detection
high-volubility high-volubility targeted sampling
conversations convesation sampler
optional arguments:
-h, --help show this help message and exit
--recordings RECORDINGS
path to a CSV dataframe containing the list of
recordings to sample from (by default, all recordings
will be sampled). The CSV should have one column named
recording_filename.
--exclude EXCLUDE path to a CSV dataframe containing the list of
segments to exclude. The columns should be:
recording_filename, segment_onset and segment_offset.
All samplers have a few parameters in common:
--recordings, which sets the white-list of recordings to sample from--exclude, which defines the portions of audio to exclude from the samples after sampling.
Periodic sampler
Draw segments from the recordings, periodically
$ child-project sampler /path/to/dataset /path/to/destination periodic --help
usage: child-project sampler path destination periodic [-h] --length LENGTH
--period PERIOD
[--offset OFFSET]
[--profile PROFILE]
optional arguments:
-h, --help show this help message and exit
--length LENGTH length of each segment, in milliseconds
--period PERIOD spacing between two consecutive segments, in milliseconds
--offset OFFSET offset of the first segment, in milliseconds
--profile PROFILE name of the profile of recordings to use to estimate
duration (uses raw recordings if empty)
Vocalization sampler
Draw segments from the recordings, targetting vocalizations from specific speaker-type(s).
$ child-project sampler /path/to/dataset /path/to/destination random-vocalizations --help
usage: child-project sampler path destination random-vocalizations
[-h] [--annotation-set ANNOTATION_SET]
[--target-speaker-type {CHI,OCH,FEM,MAL} [{CHI,OCH,FEM,MAL} ...]]
--sample-size SAMPLE_SIZE [--threads THREADS]
[--by {recording_filename,session_id,child_id}]
optional arguments:
-h, --help show this help message and exit
--annotation-set ANNOTATION_SET
annotation set
--target-speaker-type {CHI,OCH,FEM,MAL} [{CHI,OCH,FEM,MAL} ...]
speaker type to get chunks from
--sample-size SAMPLE_SIZE
how many samples per unit (recording, session, or
child)
--threads THREADS amount of threads to run on
--by {recording_filename,session_id,child_id}
units to sample from (default behavior is to sample by
recording)
Energy-based sampler
Draw segments from the recordings, targetting windows with energies above some threshold.
This algorithm proceeds by segmenting the recordings into windows; the energy of the signal is computed for each window (users have the option to apply a band-pass filter to calculate the energy in some frequency band).
Then, the algorithm samples as many windows as requested by the user from the windows that have energies above some threshold. The energy threshold is defined in term of energy quantile. By default, it is set to 0.8, i.e, only the windows with the 20% highest energies are sampled from.
The sampling is performed unit by unit, where the unit is set through
the --by option and can be any either recording_filename
(to sample an equal amount of windows from each recording),
session_id (to equally from each observing day),
or child_id (to sample equally from each child).
$ child-project sampler /path/to/dataset /path/to/destination energy-detection --help
usage: child-project sampler path destination energy-detection
[-h] --windows-length WINDOWS_LENGTH --windows-spacing WINDOWS_SPACING
--windows-count WINDOWS_COUNT [--windows-offset WINDOWS_OFFSET]
[--threshold THRESHOLD] [--low-freq LOW_FREQ] [--high-freq HIGH_FREQ]
[--threads THREADS] [--profile PROFILE]
[--by {recording_filename,session_id,child_id}]
optional arguments:
-h, --help show this help message and exit
--windows-length WINDOWS_LENGTH
length of each window (in milliseconds)
--windows-spacing WINDOWS_SPACING
spacing between the start of two consecutive windows
(in milliseconds)
--windows-count WINDOWS_COUNT
how many windows to sample from each unit (recording,
session, or child)
--windows-offset WINDOWS_OFFSET
start of the first window (in milliseconds)
--threshold THRESHOLD
lowest energy quantile to sample from. default is 0.8
(i.e., sample from the 20% windows with the highest
energy).
--low-freq LOW_FREQ remove all frequencies below low-freq before
calculating each window's energy. (in Hz)
--high-freq HIGH_FREQ
remove all frequencies above high-freq before
calculating each window's energy. (in Hz)
--threads THREADS amount of threads to run on
--profile PROFILE name of the profile of recordings to use (uses raw
recordings if empty)
--by {recording_filename,session_id,child_id}
units to sample from (default behavior is to sample by
recording)
High-Volubility sampler
Return the top windows_count windows (of length windows_length) with the highest volubility from each recording, as calculated from the metric metric.
metrics can be any of three values: words, turns, and vocs.
The words metric sums the amount of words within each window. For LENA annotations, it is equivalent to awc.
The turns metric (aka ctc) sums conversational turns within each window. It relies on lena_conv_turn_type for LENA annotations. For other annotations, turns are estimated as adult/child speech switches in close temporal proximity.
The vocs metric sums utterances (for LENA annotations) or vocalizations (for other annotations) within each window. If
metric="vocs"andspeakers=['CHI'], it is equivalent to the usual cvc metric (child vocalization counts).
$ child-project sampler /path/to/dataset /path/to/destination high-volubility --help
usage: child-project sampler path destination high-volubility
[-h] --annotation-set ANNOTATION_SET --metric {turns,vocs,words}
--windows-length WINDOWS_LENGTH --windows-count WINDOWS_COUNT
[--speakers {CHI,FEM,MAL,OCH} [{CHI,FEM,MAL,OCH} ...]]
[--threads THREADS] [--by {recording_filename,session_id,child_id}]
optional arguments:
-h, --help show this help message and exit
--annotation-set ANNOTATION_SET
annotation set
--metric {turns,vocs,words}
which metric should be used to evaluate volubility
--windows-length WINDOWS_LENGTH
window length (milliseconds)
--windows-count WINDOWS_COUNT
how many windows to be sampled from each unit
(recording, session, or child)
--speakers {CHI,FEM,MAL,OCH} [{CHI,FEM,MAL,OCH} ...]
speakers to include
--threads THREADS amount of threads to run on
--by {recording_filename,session_id,child_id}
units to sample from (default behavior is to sample by
recording)
Conversation sampler
The conversation sampler returns the conversational blocks with the highest amount of turns (between adults and the key child). The first step is the detection of conversational blocks. Two consecutive vocalizations are considered part of the same conversational block if they are not separated by an interval longer than a certain duration, which by default is set to 1000 milliseconds.
Then, the amount of conversational turns (by default, between the key child and female/male adults) is calculated for each conversational block. The sampler returns, for each unit, the desired amount of conversations with the higher amount of turns.
This sampler, unlike the High-Volubility sampler, returns portions of audio with variable durations. Fixed duration can still be achieved by clipping or splitting each conversational block.
$ child-project sampler /path/to/dataset /path/to/destination conversations --help
usage: child-project sampler path destination conversations
[-h] --annotation-set ANNOTATION_SET --count COUNT
[--interval INTERVAL]
[--speakers {CHI,FEM,MAL,OCH} [{CHI,FEM,MAL,OCH} ...]]
[--threads THREADS] [--by {recording_filename,session_id,child_id}]
optional arguments:
-h, --help show this help message and exit
--annotation-set ANNOTATION_SET
annotation set
--count COUNT how many conversations to be sampled from each unit
(recording, session, or child)
--interval INTERVAL maximum time-interval between two consecutive
vocalizations (in milliseconds) to consider them to be
part of the same conversational block. default is 1000
--speakers {CHI,FEM,MAL,OCH} [{CHI,FEM,MAL,OCH} ...]
speakers to include
--threads THREADS amount of threads to run on
--by {recording_filename,session_id,child_id}
units to sample from (default behavior is to sample by
recording)
Note
This sampler ignores LENA’s conversational turn types.